Validation Results
We validate the end-to-end extraction and labeling pipeline by comparing against manually-labeled ground truth data. This page documents the validation methodology, accuracy metrics, and known limitations.
Important: In regex-gated runs, regex is used only to detect cybersecurity-relevant sentences (mentions_cyber). All downstream labels (mentions_board, regulatory_reference, specificity) are assigned by the LLM. In LLM runs, the LLM performs both relevance detection and labeling.
Alternative experimental runs are documented on the Method Alternatives page.
AI Transparency
Validation itself uses AI: an OpenAI model (FAST_MODEL, currently gpt-4.1-mini) determines whether a bot-extracted sentence “matches” a ground truth sentence (accounting for minor text differences). This creates a second layer of AI decision-making that we document here.
Note: The tag-specific regex lists (for mentions_board, regulatory_reference, specificity) are not used for label assignment in the production pipeline. They are included as baselines or references for separate experiments.
Validation Dataset
Where do these dataset counts come from?
These four numbers are computed from the sentence_matches table in .matchquerycache.sqlite, which is produced by ground-truth-comparisons/update_matches.py.
“Transcripts validated” means the number of distinct transcript files present in the validation dataset.
SELECT COUNT(DISTINCT transcript_filename) AS transcripts_validated FROM sentence_matches; SELECT COUNT(DISTINCT ground_truth_sentence) AS ground_truth_sentences FROM sentence_matches; SELECT COUNT(DISTINCT bot_identified_sentence) AS bot_extracted_sentences FROM sentence_matches; SELECT COUNT(*) AS pairs_compared FROM sentence_matches; -- Total sentences across the validated transcripts SELECT SUM(total_sentences) AS total_sentences FROM processed_files WHERE filename IN (SELECT DISTINCT transcript_filename FROM sentence_matches);
Regex Gate Coverage (mentions_cyber)
This counts how many ground truth sentences would be missed by the mentions_cyber regex gate alone. It represents the maximum possible recall for any regex-gated run, before labeling is even considered.
| GT Sentences | Matched by Regex | Missed by Regex | Coverage |
|---|---|---|---|
| 177 | 154 | 23 | 87.0% |
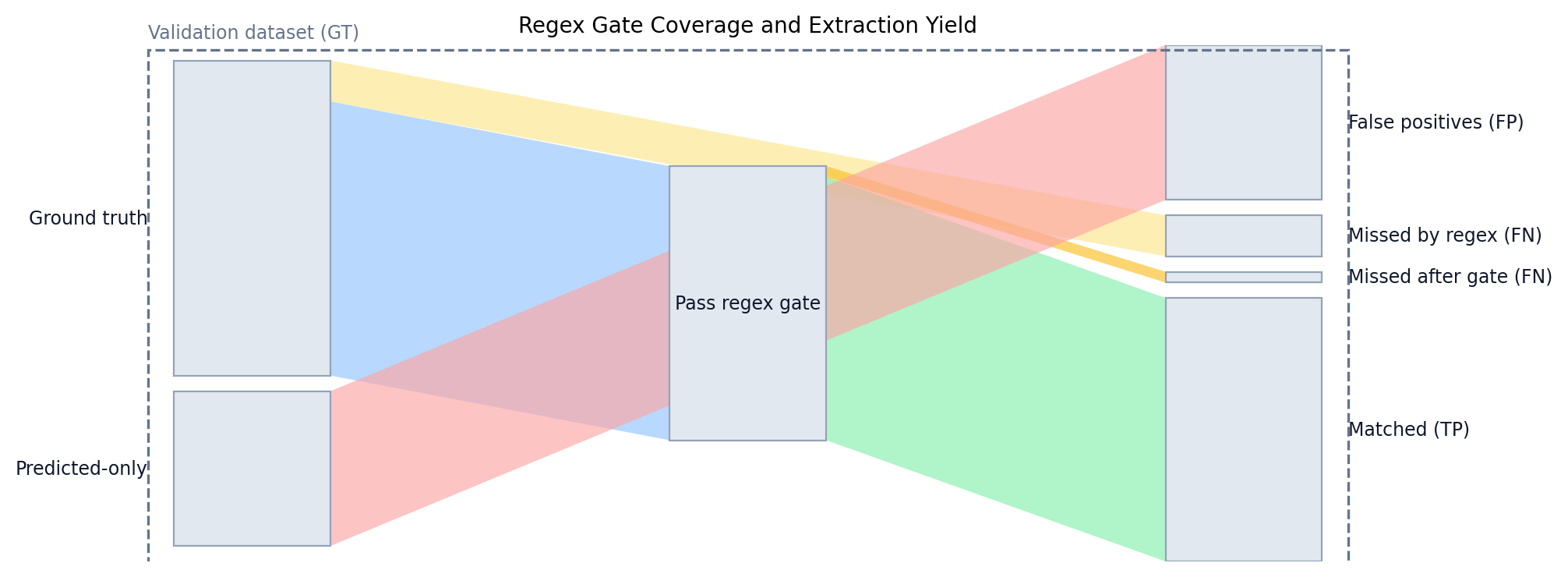
Accuracy Metrics
These metrics evaluate the full pipeline: sentence identification plus labeling. The per-tag metrics below include errors from both extraction and labeling, because a sentence must first be selected as cyber-relevant before a tag can be applied.
| Metric | Value | Interpretation |
|---|---|---|
| Precision | 63.0% | Of the bot’s positives, how many were correct |
| Recall (Coverage) | 83.6% | Share of ground truth sentences the bot found |
| F1 Score | 71.8% | Harmonic mean of precision and recall |
| Accuracy (Overlap) | 56.1% | Share of sentences in the union that match (TP / (TP+FP+FN)) |
| Bot Sentences Matched | 148 | Bot sentences that correspond to ground truth labels (TP) |
| Bot Expansion Factor | 1.3x | Bot extracts more sentences than ground truth contains |
Labeling Accuracy
These tables separate labeling quality from extraction coverage.
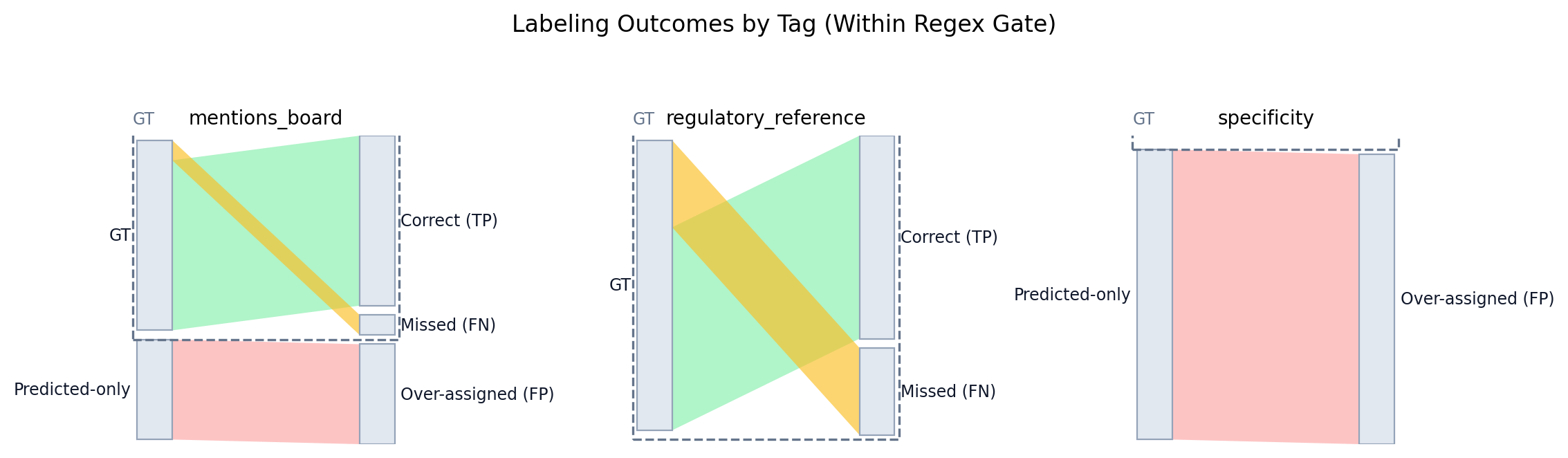
Within Regex Gate (Matched Sentences)
This table evaluates labels only for ground truth sentences that pass the mentions_cyber regex gate and were matched to an extracted sentence. Accuracy (Overlap) is TP/(TP+FP+FN) (no TNs). Accuracy (Within Matched) is (TP+TN)/(TP+FP+FN+TN) across those matched sentence pairs. The mentions_cyber row is omitted because it is guaranteed by the gate.
| Tag | Precision | Recall | F1 | Accuracy (Overlap) | Accuracy (Within Matched) | TP | FP | FN | TN | GT | AI |
|---|---|---|---|---|---|---|---|---|---|---|---|
| mentions_board | 63.0% | 89.5% | 73.9% | 58.6% | 91.9% | 17 | 10 | 2 | 119 | 19 | 27 |
| regulatory_reference | 100.0% | 70.0% | 82.4% | 70.0% | 98.0% | 7 | 0 | 3 | 138 | 10 | 7 |
| specificity | 0.0% | 0.0% | 0.0% | 0.0% | 68.2% | 0 | 47 | 0 | 101 | 0 | 47 |
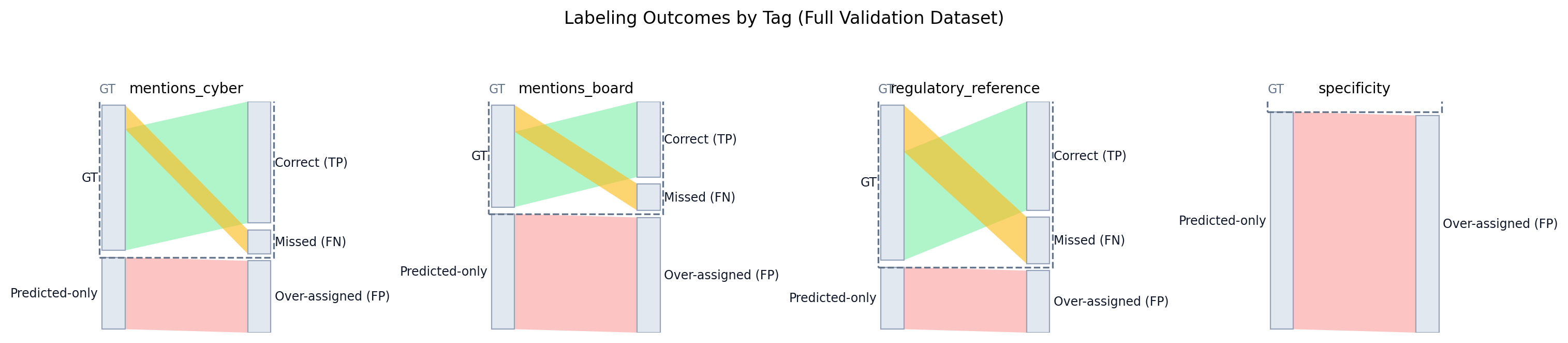
Full Validation Dataset (Missing Gate = Fail)
This table evaluates labeling performance across the entire validation dataset. If a sentence is missed by the regex gate, its tags count as false negatives. Accuracy (Overlap) is TP/(TP+FP+FN).
| Tag | Precision | Recall | F1 | Accuracy (Overlap) | TP | FP | FN | GT | AI |
|---|---|---|---|---|---|---|---|---|---|
| mentions_cyber | 62.8% | 83.5% | 71.7% | 55.9% | 147 | 87 | 29 | 176 | 234 |
| mentions_board | 39.5% | 73.9% | 51.5% | 34.7% | 17 | 26 | 6 | 23 | 43 |
| regulatory_reference | 63.6% | 70.0% | 66.7% | 50.0% | 7 | 4 | 3 | 10 | 11 |
| specificity | 0.0% | 0.0% | 0.0% | 0.0% | 0 | 92 | 0 | 0 | 92 |
Validation by Transcript
Performance varies by transcript. The plot below shows recall (x-axis) vs precision (y-axis), with each dot representing a transcript. Colors indicate industry when known.
The table below lists transcript-level counts, including total sentences, regex-gated sentences, and tag totals.
| Transcript | Company | Industry | Total Sentences | Regex Matched | mentions_cyber | mentions_board | regulatory_reference | specificity | Precision | Recall | TP | FP | FN | GT | AI | Pairs Checked |
|---|
Quality Assurance Process
Ground Truth Collection
Human researchers manually labeled cybersecurity-relevant sentences in a subset of transcripts, applying the same label categories (mentions_board, regulatory_reference, specificity).
Sentence Matching
An OpenAI model (FAST_MODEL, currently gpt-4.1-mini, temperature=0) compares each ground truth sentence against each bot-extracted sentence to determine if they represent the same content (accounting for tokenization differences and minor text variations). Match decisions are stored in sentence_matches.
Overseer QA
An "overseer" model reviews ground truth sentences that the bot skipped, evaluating whether the miss was justified or indicates a systematic gap.
Pattern Analysis
We train classifiers on missed sentences to identify phrase patterns associated with false negatives, informing prompt refinement.
Known Issues
- Sentence boundary mismatches: Different tokenizers split sentences at different points
- Context-dependent references: Pronouns like "it" referring to cybersecurity may be missed
- Implicit mentions: "The incident" referring to a known breach may not be detected without context
- Ground truth limitations: Human labeling may also miss relevant sentences or include marginal ones
Continuous Improvement
Validation findings feed back into prompt engineering and processing improvements:
- Identified patterns in missed sentences inform keyword list expansion
- Context window size adjustments improve detection of implicit references
- Label criteria refinements reduce classification ambiguity